|

总有那么一些细节,你瞪大双眼拼了命想看清却依然奈不了何,比如下面这个:

跟得上球吗?要看清男子羽毛球比赛的细节实在不容易
有时候想盯住飞来飞去的羽毛球,非常吃力,这就是人类肉眼的极限。
你或许会说,好解决啊,用慢速回放功能就行了。
确实可以回放,但慢速回放的前提,是摄像机一开始就捕捉到了这些细节。如今,一些大型体育赛事已经用上了工业高速摄像头,为的就是在裁判的裁决引发争议时,可以用慢镜头回放来判定结果。
但是,没有专业的高速摄像头怎么办?
像我们用智能手机拍的视频,记录下生活中很多美好,随风飘逝的晚霞,又或者池塘溅起的涟漪,还有孩子们在泳池里泼水嬉戏,如果都能够放慢了观看,必将带来全新的感受。
正因如此,当今年计算机视觉顶会CVPR举行时,英伟达团队的一篇能让手机拍摄的视频也“高清慢速播放”的论文,在业界引发了很大的反响。

这项被称为Super SloMo的工作,使用深度神经网络,对视频中缺失的帧进行预测并补全,从而生成连续慢速回放的效果。
更赞的是,他们提出的方法,能够排除原视频帧当中被遮挡的像素,从而避免在生成的内插中间帧里产生模糊的伪像(artifact)。
值得一提,这篇论文的第一作者,是本硕毕业于西安交通大学、现在马萨诸塞大学阿默斯特分校读博四的 Huaizu Jiang。第二作者 Deqing Sun 是英伟达学习与感知研究小组的高级研究员,本科毕业于哈工大,硕士读的港中文,在布朗大学取得博士学位后,在哈佛 Hanspeter Pfister 教授的视觉研究小组做过博士后。
感受一下Super-SloMo生成的“慢速回放”效果:

注意,左右两边都是Super SloMo生成的视频。左边是原始慢速视频,右边是将这个结果再放慢4倍的效果,如果不告诉你中间的细节(帧)是神经网络生成的,你会不会把它们当做真的慢速回放?来源:Huaizu Jiang个人主页

实际用手机拍摄的画面是这样的,对比后,意识到Super SloMo补充多少细节了吗?
论文作者称,他们能将30FPS(画面每秒帧数)的视频变为480FPS,也即每秒帧数增加了16倍。
根据Super SloMo项目主页,作者表示,使用他们未经优化的PyTorch代码,在单个NVIDIA GTX 1080Ti 和 Tesla V100 GPU上,生成7个分辨率为1280*720的中间帧,分别只需要0.97秒和0.79秒。(补充说明:从标准序列30-fps生成240-fps视频,一般需要在两个连续帧内插入7个中间帧。)
Super SloMo效果展示。来源:NVIDIA
效果当然称得上惊艳。然而,令很多人失望的是,论文发布时并没有将代码和数据集公开,尽管作者表示可以联系 Huaizu Jiang 获取部分原始资料。

仅在论文中提到的数据和示例。来源:Super SloMo论文
今天,有人在 Github 上开源了他对 Super-SloMo 的 PyTorch 实现。这位ID为atplwl的Reddit用户,在作者提供的adobe24fps数据集上预训练的模型(下图中pretrained mine),实现了与论文描述相差无几的结果。

现在,这个预训练模型,还有相关的代码、数据集,以及实现条件,都能在GitHub上查到。
自称新手的atplwl表示,他目前在努力完善这个GitHub库,接下来预计添加一个PyThon脚本,将视频转换为更高的fps视频,欢迎大家提供建议。
Super SloMo PyTorch实现地址(点击阅读原文访问):https://github.com/avinashpaliwal/Super-SloMo
Super SloMo:将任意视频变为“高清慢速播放”
代码在手,再看论文——前文已经说过,从已有视频中生成高清慢速视频是一件非常有意义的事情。
除了专业的高速摄像机尚未普及到每个人手里,人们用手机拍摄的视频 (一般为240FPS) 想要放慢的时刻是不可预测的,要实现这一点就不得不用标准帧速率来记录所有视频,但这样做需要的内存过大,对移动设备来说耗电量也花不起。
现在,计算机视觉领域,除了将标准视频转换为更高的帧速率之外,还可以使用视频插值来生成平滑的视图转换。在自监督学习中,这也可以作为监控信号来学习未标记视频的光流。
不过,生成多个中间视频帧 (intermediate video frame) 是具有挑战性的,因为帧必须在空间和时间上是连贯的。例如,从30-fps标准序列生成240-fps视频,需要在两个连续帧内插入7个中间帧。
成功的解决方案不仅要正确解释两个输入图像之间的运动(隐式或显式),还要理解遮挡 (occlusion)。 否则,就可能导致插值帧中产生严重的伪像,尤其是在运动边界附近。
现有方法主要集中于单帧视频插值,而且已经取得了不错的进展。然而,这些方法不能直接用于生成任意高帧率视频。
虽然递归地应用单帧视频插值方法生成多个中间帧是一个很不错的想法,但这种方法至少有两个限制:
首先,递归单帧插值不能完全并行化,速度较慢,因为有些帧是在其他帧完成后才进行计算的(例如,在七帧插值中,帧2取决于0和4,而帧4取决于0和8)。 其次,它只能生成2i-1个中间帧。因此,不能使用这种方法有效生地生成1008 - fps 24帧的视频,这需要生成41中间帧。
论文 Super SloMo: High Quality Estimation of Multiple Intermediate Frames for Video Interpolation 提出了一种高质量的变长多帧插值方法,该方法可以在两帧之间的任意时间步长进行插值。
其主要思想是,将输入的两幅图像扭曲到特定的时间步长,然后自适应地融合这两幅扭曲图像,生成中间图像,其中的运动解释和遮挡推理在单个端到端可训练网络中建模。

Super SloMo效果展示:注意在放慢过渡区域对伪像的处理。
具体来说,首先使用流量计算CNN来估计两幅输入图像之间的双向光流,然后线性融合来近似所需的中间光流,从而使输入图像发生扭曲。这种近似方法适用于光滑区域,但不适用于运动边界。
因此,Super SloMo 论文作者使用另一个流量插值CNN来细化流近似并预测软可见性图。
通过在融合之前将可见性图应用于变形图像,排除了被遮挡像素对内插中间帧的贡献,从而减少了伪像。
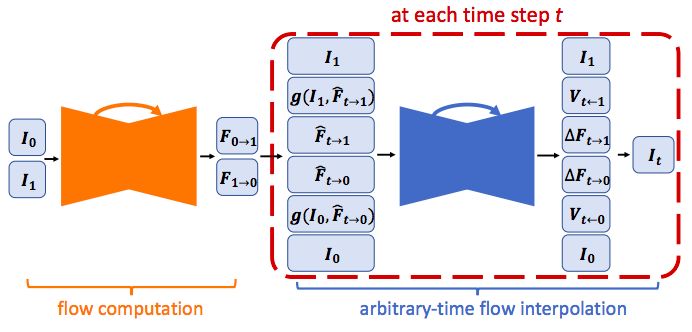
Super SloMo网络架构
“我们的流计算和插值网络的参数都独立于被插值的具体时间步长,是流插值网络的输入。因此,我们的方法可以并行生成任意多的中间帧。”作者在论文中写道。
为了训练该网络,团队从YouTube和手持摄像机收集了240-fps的视频。总量有1.1K视频剪辑,由300K个独立视频帧组成,典型分辨率为1080×720。
然后,团队在其他几个需要不同插值数量的独立数据集上评估了训练模型,包括Middlebury 、 UCF101 、慢流(slowflow)数据集和高帧率(high-frame-rate) MPI Sintel。
实验结果表明,该方法明显优于所有数据集上的现有方法。 团队还在KITTI 2012光流基准上评估了无监督(自监督)光流结果,并获得了比现有最近方法更好的结果。
Super SloMo项目主页:https://people.cs.umass.edu/~hzjiang/projects/superslomo/ Super SloMo PyTorch实现Github地址: https://github.com/avinashpaliwal/Super-SloMo | 


 发表于 2019-1-4 10:09:27
发表于 2019-1-4 10:09:27