|
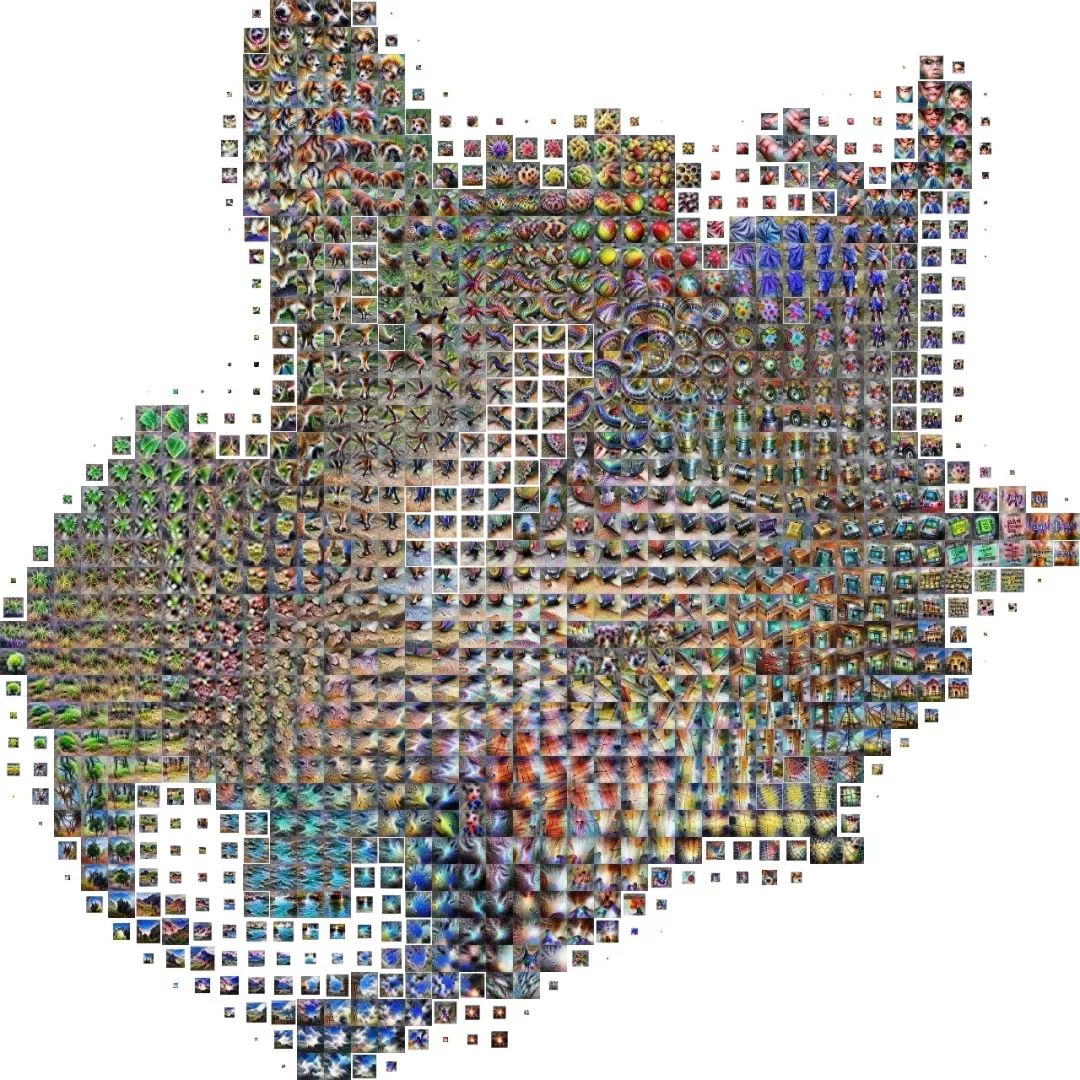
AI眼中的世界就是激活地图(Activation Atlases)。
近日,谷歌与OpenAI共同创建了Activation Atlases,这是一种可视化神经元之间相互作用的新技术。通过使用特征反演(feature inversion)来可视化一个图像分类网络中数以百万计的激活。
换言之,神经网络图像分类的黑匣子终于被打开了。这将有助于研究人员更好的理解AI系统在内部决策的过程。
Activation Atalas:神经网络隐藏层可以表示什么
我们先来看下以往的工作的一些缺陷:
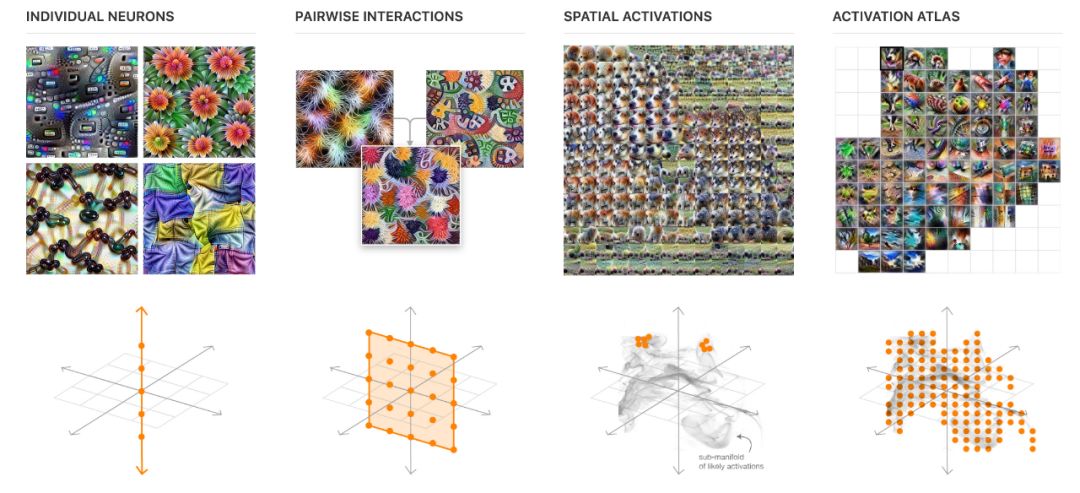
(单个神经元)单个神经元的可视化使隐藏层变得有意义,但是忽略了神经元之间的交互作用——它只向我们展示了高维激活空间的一维正交探针。(成对交互)成对的交互揭示了相互作用的效果,但它们只显示了具有数百个维度空间的二维切片,而且许多组合是不现实的。(空间激活)空间激活通过对可能激活的子流形进行采样来向我们显示许多神经元的重要组合,但它们仅限于给定示例图像中出现的那些神经元。(Activation Atlas)通过对多种可能的激活进行采样,Activation Atlase为我们提供了一个更全面的概览。
Activation Atalas是建立在特征可视化的基础上,这是一种研究“神经网络隐藏层可以表示什么”的技术。
在深入研究Activation Atalas之前,先简要回顾一下如何使用特征可视化使激活向量变得有意义,也就是如何“透过网络的眼睛看”事物。 这种技术将成为Activation Atalas的基础。 注:本文关注的神经网络是InceptionV1,也称GoogLeNet。
因为InceptionV1是一个卷积网络,每层每幅图像都不只有一个激活向量。
这意味着相同的神经元运行在前一层的每个patch上。因此,当通过网络传递整幅图像时,每个神经元将被评估数百次,每一个重叠的图像块被评估一次。

结果是一个特征可视化网格,每个patch都有一个。这向我们展示了网络如何看到输入图像的不同部分。

(左)从ImageNet输入的图像;(右)来自InceptionV1的激活网格,mixed4d层。
这是单幅图像的情况,但如果图像的数量是数以百万计的,那么AI的反应又将如何呢?
先从收集一百万个图像的激活开始。
我们将随机为每张图像选择一个空间激活。这就得到了100万个激活向量。每个向量都是高维的,可能是512维!对于如此复杂的一组数据,如果我们想要一个大的视图,就需要对其进行组织和聚合。
通过一些先进的降维技术,可以将收集到的激活向量投影到有用的二维布局中,并保留原始空间的一些局部结构。将在创建的2D布局上绘制网格,对于网格中的每个单元格,将位于该单元格边界内的所有激活平均化,并使用特征可视化来创建图标表示。
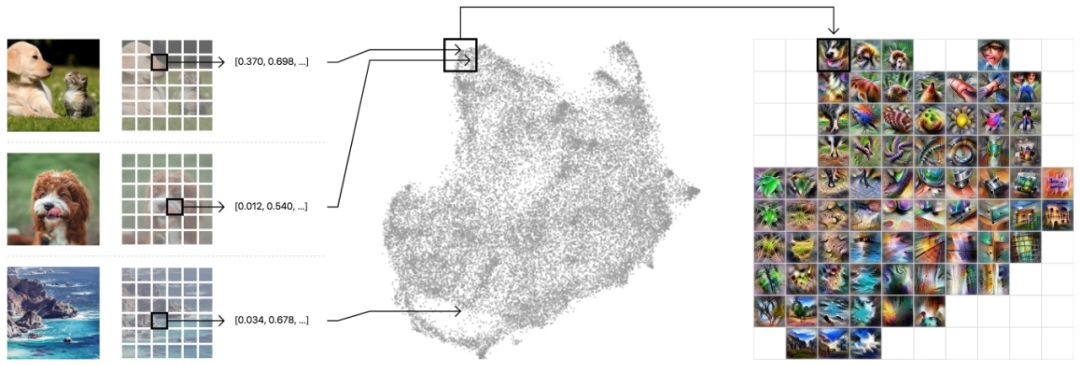
(左)从不同的训练示例中收集100万个激活向量。 (中)将它们排列成2D,以便让相似的元素更紧密地排列在一起。 (右)对每个单元格的平均添加网格,并对其进行特征可视化。

mixed4c层,应用到InceptionV1,从左至右:20x20,40x40,80x80,160x160。
这幅地图集乍一看可能有点让人不知所措,这种多样性反映了模型开发的各种抽象和概念。
如果我们看一下地图集的左上方,我们会看到看起来像动物头部的东西。
不同种类的动物之间有一些区别,但似乎更多的是一些普通哺乳动物的元素——眼睛、皮毛、鼻子——而不是不同种类动物的集合。

随着我们向下移动,我们开始看到不同类型的毛皮和四足动物的背部。

在此之下,我们发现不同的动物腿和脚在不同的地面上休息。

在脚的下面,我们开始失去任何可识别的动物部分,并看到孤立的地面和地板。 我们看到归属于“沙洲”等环境以及地面上发现的东西,如“门垫”或“蚂蚁”。

这些沙质岩石背景慢慢地融入海滩和水体。 在这里,我们可以看到水面上下的湖泊和海洋。虽然神经网络上确实有“海滨”这样的特定类别,但我们看到许多海洋动物的属性,而没有任何与动物本身有关的视觉参考。
但令人欣慰的是,用于为“海滨”类识别海洋的活动与用于分类“海星”或“海狮”的活动是相同的。在这一点上,湖泊和海洋也没有真正的区别——“湖边”和“河马”的属性与“海星”和“黄貂鱼”混杂在一起。
早期的特征可视化工作主要集中在单个神经元上。而通过收集成千上万个神经元相互作用的例子并将其可视化,Activation Atalas从单个神经元转移到这些神经元共同代表的空间。
现在让我们跳到地图集的另一边,在那里我们可以看到许多不同的文本检测器。当识别诸如“菜单”、“web站点”或“book jacket”之类的类时,这些检测器将非常有用。

再向上看,可以看到许多不同的人。在ImageNet中很少有专门识别人员的类,但人们会出现在很多图像中。
我们看到人们使用的物品(“锤子”、“笛子”)、人们穿的衣服(“领结”、“邮筒”)以及人们参加的活动(“篮球”)的属性。在这些可视化中,肤色是一致的,我们怀疑这反映了用于训练的数据的分布。
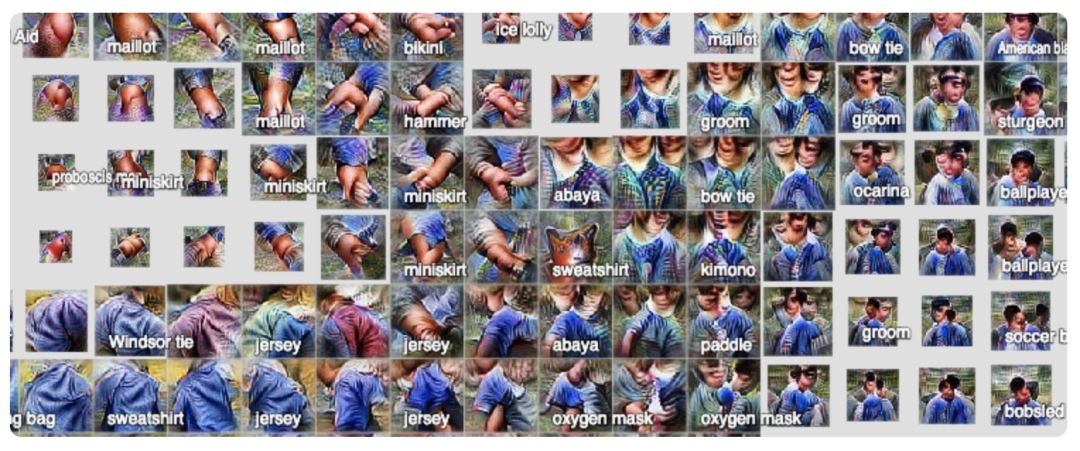
最后,回到左边,我们可以看到圆形的食物和水果主要是由颜色组成的——我们看到归属于“柠檬”、“橘子”和“无花果”。

上述工作中,我们主要关注网络的一个层——mixed4c,它位于网络的中间。而卷积网络通常很深,由许多层组成,且逐步构建更强大的抽象。 为了获得整体视图,我们必须研究模型的抽象是如何在多个层次上发展的。
首先,让我们比较来自网络不同区域的三个层,以了解每个层的不同特征——mixed3b、mixed4c和mixed5b。我们将关注每层的有助于“卷心菜”分类的区域。

当在网络中移动时,后面的层似乎变得更加具体和复杂。
因为每个层都在前一层的激活之上构建其激活。后一层的接受域也往往比前一层更大(这意味着图像的子集更大),因此概念似乎包含了更多的整体对象。
还有另一个值得注意的现象:不仅概念正在被提炼,而且新概念正在从旧概念的组合中出现。

最后,如果我们缩小一点,我们可以看到更宽的激活空间的形状是如何从一层到另一层变化的。通过在几个连续的层中观察相似的区域,我们可以看到概念得到细化和区分——在mixed4a中,我们看到非常模糊的通用blob,通过mixed4e将其细化为更加具体的“半岛”。

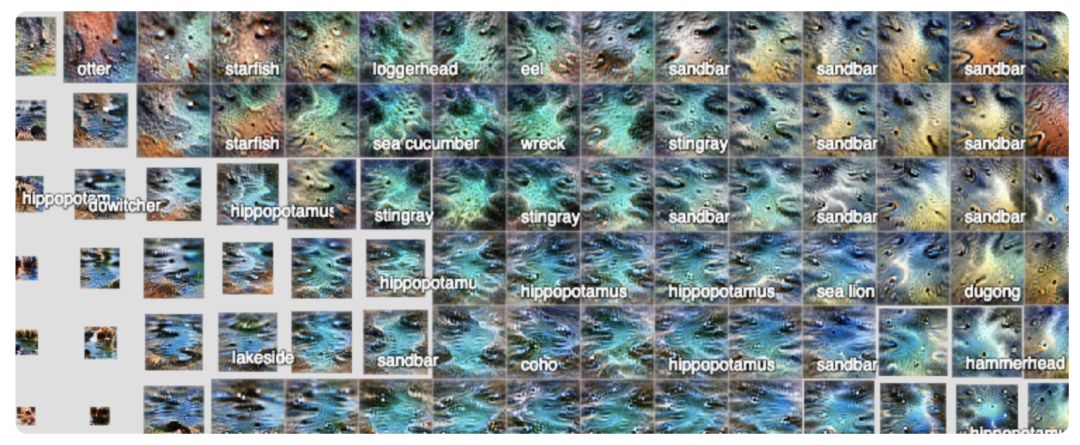
激活地图中,类的边界是导致神经网络容易“误认”主要原因
突出显示完整地图集的特定类别激活有助于了解该类如何与网络“可以看到”的完整空间相关联。
但是,如果我们想要真正隔离有助于特定类的激活,我们 可以删除所有其他激活。与一般地图集类似,我们在类特定激活向量上运行维数减少5,以便排列类激活图集中显示的特征可视化。

类激活图集使我们能够更清楚地了解网络使用哪些检测器对特定类进行排名。 在“呼吸管”示例中,我们可以清楚地看到海洋、水下和彩色面具。
不过,在某些情况下,我们希望看到有很强的相关性(比如鱼和潜水者)。这些激活本身可能比我们感兴趣的类对不同的类有更强的贡献,但是它们的存在也可以对我们感兴趣的类有更大的贡献。
对于这些,我们需要选择一种不同的过滤方法。

要立即理解类之间的所有差异可能有点困难。为了便于比较,我们可以将这两个视图合并为一个视图。我们将在水平方向绘制“snorkel”和“scuba diving”属性之间的差异,并使用t-SNE在垂直方向聚集类似的活动。

在这个对比中,我们可以看到一些鸟一样的生物和左边清晰的管子,暗示着与“snorkel”有关,而一些鲨鱼一样的生物和右边圆形、闪亮、金属的东西,暗示着与“scuba driver”有关。
让我们从标记为“snorkel”的ImageNet数据集中获取一张图像,并添加类似于此图标的内容,以查看它如何影响分类分数。
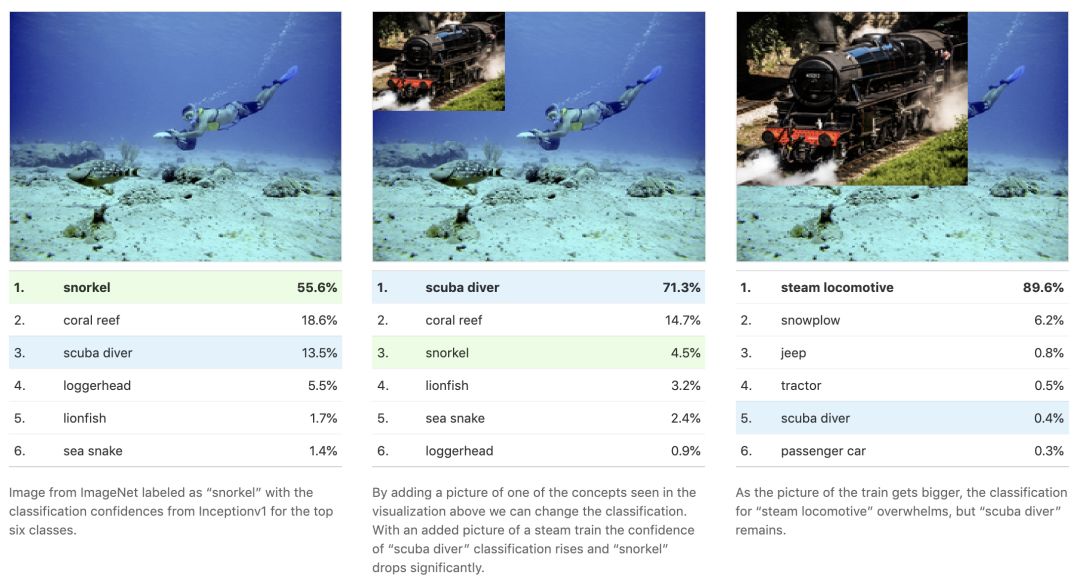
这里的失效模式似乎是该模型正在使用其探测器用于“蒸汽机车”类来识别空气罐以帮助对“潜水员”进行分类。
我们称之为“多用途”功能 - 探测器可以对视觉上相似的非常不同的概念做出反应。 让我们来看看“灰鲸”和“大白鲨”之间的区别,看看这个问题的另一个例子。
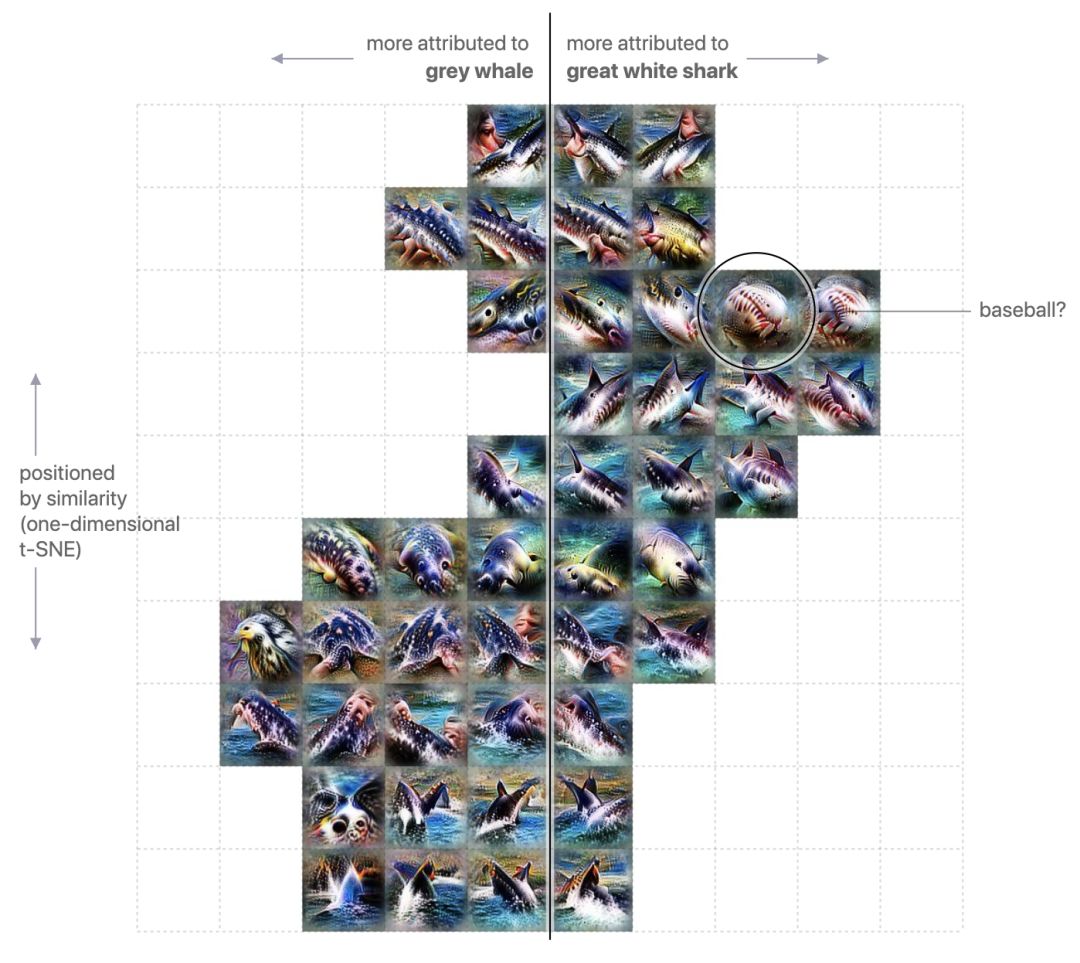
在这个例子中,我们看到另一个似乎扮演两个角色的探测器:探测棒球上的红色缝线和鲨鱼的白色牙齿和粉红色的内口。
这个探测器也出现在激活地图集层混合5b过滤到“大白鲨”,它的归属点是各种各样的球,最重要的是“棒球”。
让我们将棒球图片添加到ImageNet中的“灰鲸”图片中,看看它是如何影响分类的。
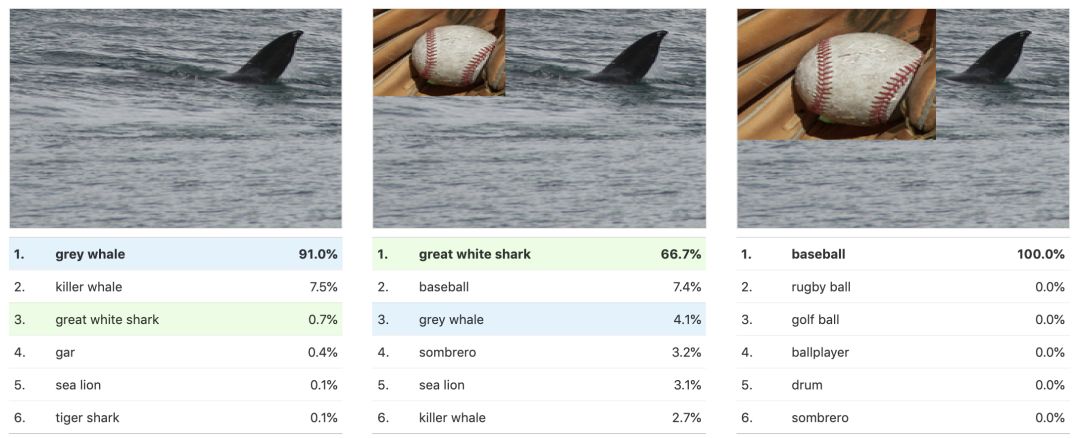
所以,这也就是为什么神经网络经常总会认错东西了。
| 


 发表于 2019-3-14 19:22:27
发表于 2019-3-14 19:22:27