|
众所周知,神经网络十分擅长处理特定领域的任务 (narrow task),但在处理多任务时结果并不是那么理想。
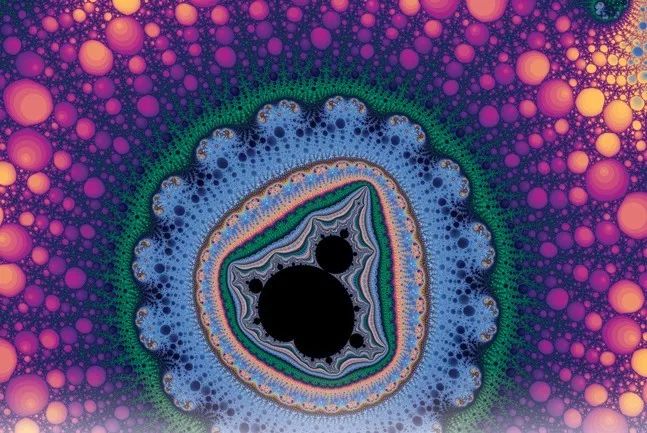
这与人类的大脑不同,人类的大脑能够在多样化任务中使用相同的概念。例如,假如你从来没听说过 “分形”(fractal),请看下面这张图:
数学之美:分形图像
上图是一个分形图像。在看到一张分形图像后,人能够处理多个与之相关的任务: 在一组图像中,区分一只猫的图像和分形图像; 在一张纸上,粗略地画一个分形图像; 将分形图像与非分形图像进行分类; 闭上眼睛,想象一下分形图像是什么样子的。
那么,你是如何完成这些任务的呢?大脑中有专门的神经网络来处理这些任务吗?
现代神经科学认为,大脑中的信息是在不同的部位进行分享和交流的。对于这种多任务性能是如何发生的,答案可能在于如何在神经网络中存储和解释数据。
顾名思义,“表示”(representation) 就是信息在网络中编码的方式。当一个单词、一个句子或一幅图像 (或其他任何东西) 作为输入提供给一个训练好的神经网络时,它就随着权重乘以输入和应用激活在连续的层上进行转换。最后,在输出层,我们得到一串数字,我们将其解释为类的标签或股票价格,或网络为之训练的任何其他任务。
输入 -> 输出的神奇转换是由连续层中发生的输入转换产生的。输入数据的这些转换即称为 “表示”(representations)。一个关键的想法是,每一层都让下一层更容易地完成它的工作。使连续层的周期变得更容易的过程会导致激活 (特定层上输入数据的转换) 变得有意义。
有意义是指什么呢?让我们看下面的示例,该示例展示了图像分类器中不同层的激活。

图像分类网络的作用是将像素空间中的图像转化为更高级的概念空间。例如,一张汽车的图像最初被表示为 RGB 值,在第一层开始被表示为边缘空间,然后在第二层被表示为圆圈和基本形状空间,在倒数第二层,它将开始表示为高级对象 (如车轮、车门等)。
这种越来越丰富的表示 (由于深度网络的分层性质而自动出现) 使得图像分类的任务变得简单。最后一层要做的就是斟酌,比如说,车轮和车门的概念更像汽车,耳朵和眼睛的概念更像人。
你能用这些表示做什么 ?
由于这些中间层存储有意义的输入数据编码,所以可以对多个任务使用相同的信息。例如,你可以使用一个语言模型 (一个经过训练的、用于预测下一个单词的递归神经网络),并解释某个特定神经元的激活,从而预测句子带有的情绪。
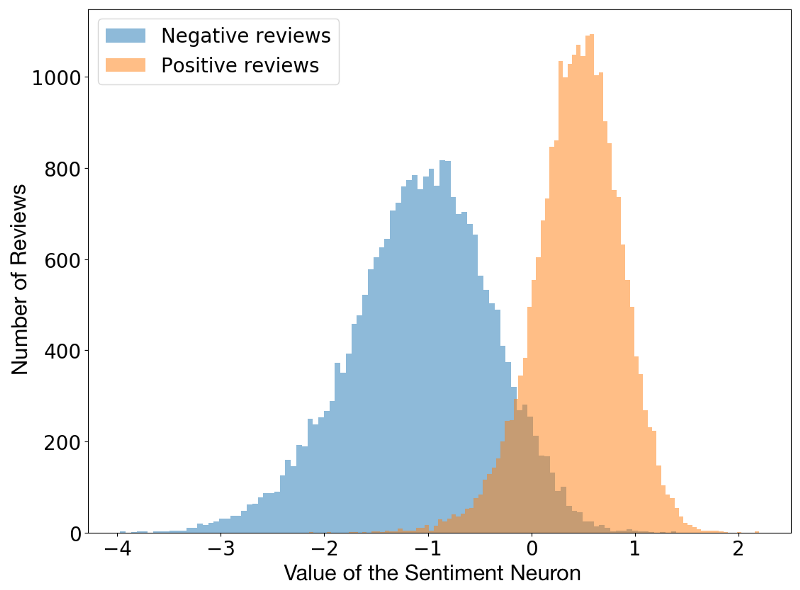
一个令人惊讶的事实是,情感神经元是在无监督的语言建模任务中自然产生的。网络被训练去预测下一个单词,它的任务中并没有被要求去预测情感。也许情感是一个非常有用的概念,以至于网络为了更好地进行语言建模而发明它。
一旦你理解了 “表示” 这个概念,你就会开始从完全不同的角度来理解深层神经网络。你会开始将感知表示 (sensing representations) 作为一种可转换的语言,使不同的网络(或同一网络的不同部分) 能够彼此通信。
为了充分理解 “表示”,让我们来构建一个能同时完成四个任务的的深度神经网络:
图像描述生成器:给定图像,为其生成描述 相似单词生成器:给定一个单词,查找与之相似的其他单词 视觉相似的图像搜索:给定一幅图像,找出与之最相似的图像 通过描述图像内容进行搜索:给出文本描述,搜索具有所描述的内容的图像
这里的每一个任务本身就是一个项目,传统上分别需要一个模型。但我们现在要用一个模型来做所有这些任务。
Pytorch 代码: https://github.com/paraschopra/one-network-many-uses
第一部分:看图说话 (Image Captioning)
在网上有很多实现 Image Captioning 的很好的教程,所以这里不打算深入讲解。我的实现与这个教程中的完全相同:https://daniel.lasiman.com/post/image-captioning/。关键的区别在于,我的实现是在  ytorch 中实现的,而这个教程使用的是 Keras。 ytorch 中实现的,而这个教程使用的是 Keras。
接下来,你需要下载 Flickr8K 数据集。你还需要下载图像描述。提取“caption_datasets” 文件夹中的文字描述。
模型
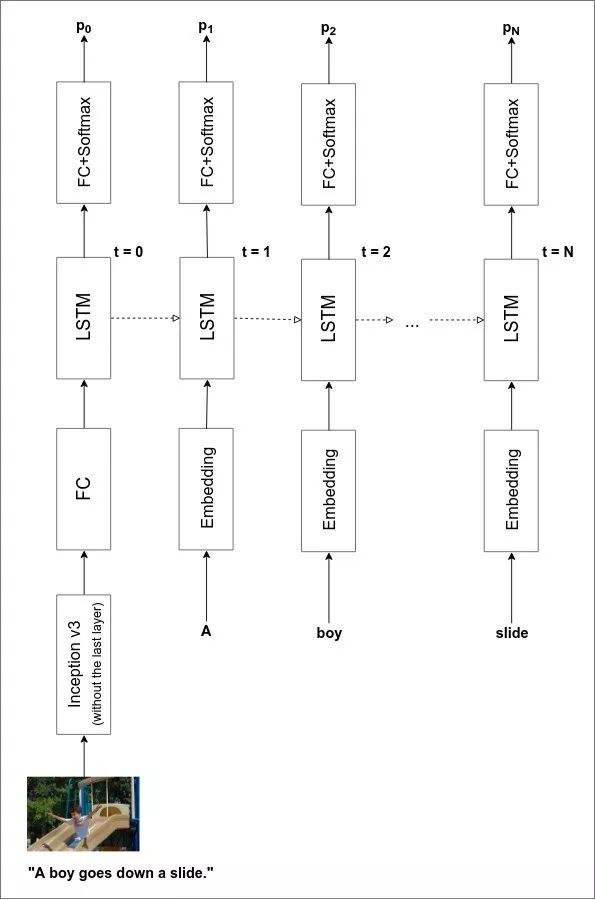
Image Captioning 一般有两个组成部分: a) 图像编码器 (image encoder),它接收输入图像并以一种对图像描述有意义的格式来表示图像; b) 图说解码器 (caption decoder),它接受图像表示,并输出文本描述。
image encoder 是一个深度卷积网络,caption decoder 则是传统的 LSTM/GRU 递归神经网络。当然,我们可以从头开始训练它们。但这样做需要比我们现有的 (8k 图像)更多的数据和更长的训练时间。因此,我们不从头开始训练图像编码器,而是使用一个预训练的图像分类器,并使用它的 pre-final 层的激活。
这是一个示例。我使用 yTorch modelzoo 中可用的 Inception 网络,该网络在ImageNet 上进行了训练,可以对 100 个类别的图像进行分类,并使用它来提供一个可以输入给递归神经网络中的表示。
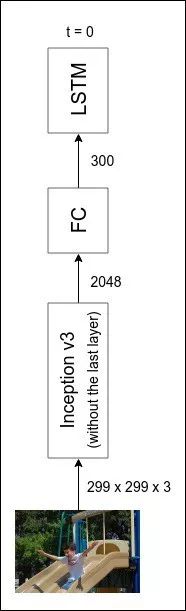
请注意,Inception network 从未针对图说生成任务进行过训练。然而,它的确有效!
我们也可以使用一个预训练的语言模型来作为 caption decoder。但这一次,由于我重新实现了一个运行良好的模型,所以可以从头开始训练解码器。
完整的模型架构如下图所示:
你可以从头开始训练模型,但是需要在 CPU 上花费几天时间 (我还没有针对 GPU 进行优化)。但不用担心,你也可以享受一个已经训练完成的模型。(如果你是从头开始训练,请注意,我在大约 40 epochs 时停止训练,当时运行的平均损失约为 2.8)。
性能
我实现了性能良好的 beam search 方法。下面是网络为测试集中的图像生成的图说示例(以前从未见过)。


用我自己的照片试试,让我们看看网络生成的图说是什么:

效果不错!令人印象深刻的是,网络知道这张照片里有一个穿着白色 T 恤的男人。但语法有点偏离 (我相信通过更多的训练可以修正),但基本的要点抓住了。
如果输入的图像包含网络从未见过的东西,它往往会失败。例如,我很好奇网络会给iPhone X 的图像贴上什么样的标签。
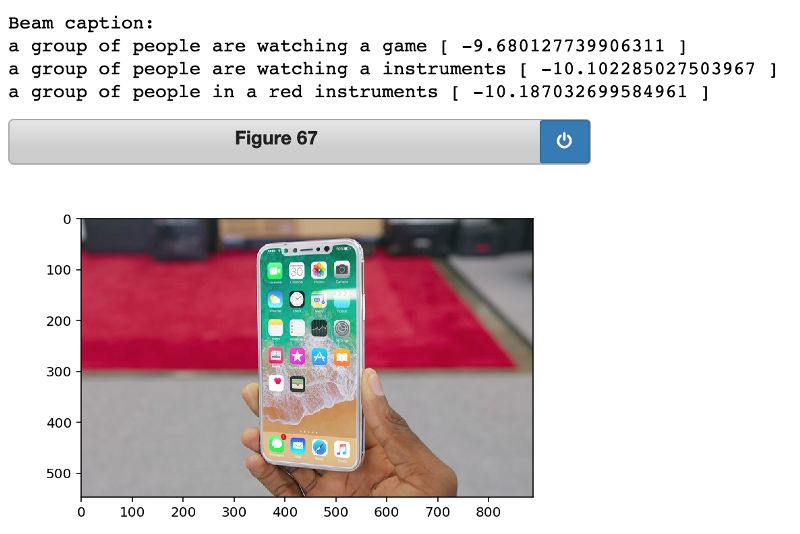
效果不太好。但总的来说,我对它的表现非常满意,这为我们使用网络在学习给图像生成图说时开发的 “表示” 来构建其他功能提供了良好的基础。
回想一下我们如何从图像表示中解码图说。我们将该表示提供给 LSTM/GRU 网络,生成一个输出,将其解释为第一个单词,然后将第一个单词返回到网络以生成第二个单词。这个过程一直持续到网络生成一个表示句子结束的特殊标记为止。
为了将单词反馈到网络中,我们需要将单词转换为表示,再输入给网络。这意味着,如果输入层包含 300 个神经元,那么对于所有图说中的 8000 多个不同的单词,我们需要有一个 300 个相关联的数字,唯一地指定那个单词。将单词字典转换成数字表示的过程称为词汇嵌入 (或词汇表示)。
我们可以下载和使用已经存在的词汇嵌入,如 word2vec 或 GLoVE。但在这个示例中,我们从头开始学习词汇嵌入。我们从随机生成的词汇嵌入开始,探索在训练结束时,网络对单词的了解。
由于我们无法想象 100 维的数字空间,我们将使用一种称为 t-SNE 的奇妙技术来在 2维中可视化学习的词汇嵌入。t-SNE 是一种降维技术,它试图使高维空间中的邻域同时也是低维空间中的邻域。
词汇嵌入的可视化
让我们来看看 caption decoder 学习到的词汇嵌入空间 (不像其他语言任务有数百万单词和句子,我们的解码器在训练数据集中只有 ~30k 的句子)。
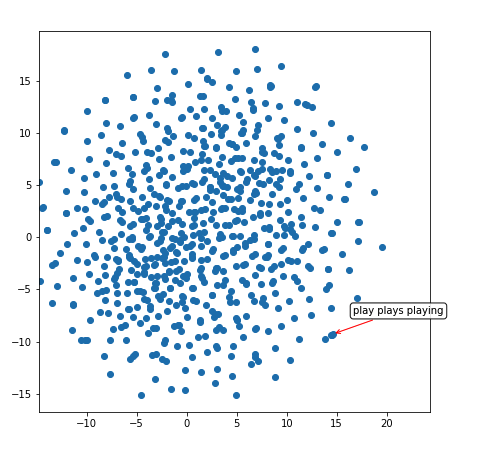
因此,我们的网络已经了解到像 “play”、“plays” 和 “playing” 这样的词汇是非常相似的 (它们具有相似的表示形式,如红色箭头所示的紧密聚类)。让我们在这个二维空间中探索另一个区域:
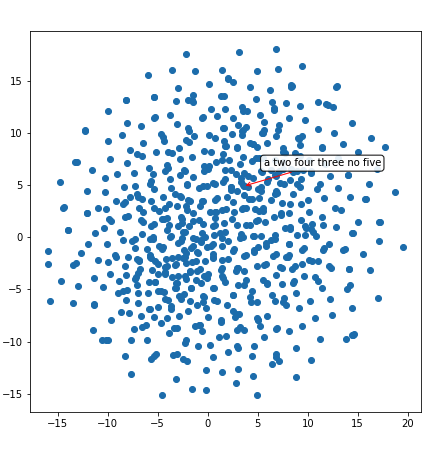
这个区域似乎有一堆数字 ——“two”、“three”、“four”、“five”,等等。
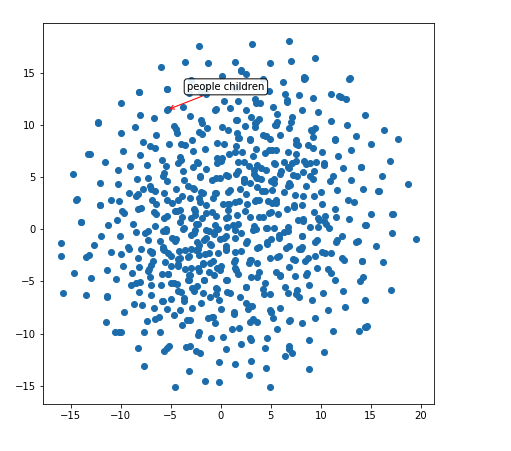
上图,它知道 people 和 children 两个单词相似。而且,它还隐式地推断出了物体的形状。

相似词汇
我们可以使用 100 维表示 (100-dimensional representation) 来构建一个函数,该函数提出与输入单词最相似的单词。它的工作原理很简单:采用 100 维的表示,并找出它与数据库中所有其他单词的余弦相似度。
让我们来看看与 “boy” 这个单词最相似的单词:
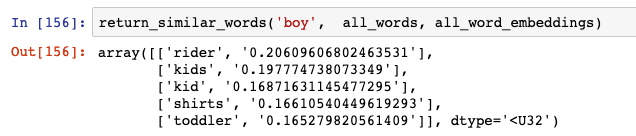
结果不错。“Rider” 除外,但 “kids”、“kid” 和 “toddler” 都是正确的。
这个网络认为与 “chasing” 相似的词汇是:
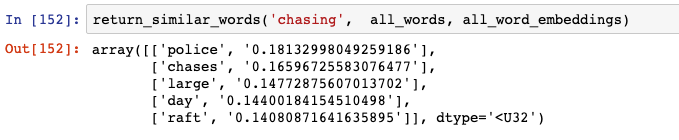
“Chases” 是可以的,但我不确定为什么它认为 “police” 与 “chasing” 类似。
单词类比 (Word analogies)
关于词汇嵌入的一个令人兴奋的事实是,你可以对它们进行微积分。你可以用两个单词(如 “king” 和 “queen”) 并减去它们的表示来得到一个方向。当你把这个方向应用到另一个词的表示上 (如 “man”),你会得到一个与实际类似词 (比如 “woman”) 很接近的表示。这就是为什么 word2vec 一经推出就如此受欢迎的原因:
我很好奇通过 caption decoder 学习到的表示是否具有类似的属性。尽管我持怀疑态度,因为训练数据并不大 (大约 3 万个句子),我还是尝试了一下。
网络学习到的类比并不完美 (有些单词字面上出现的次数<10 次,所以网络没有足够的信息可供学习)。但仍有一些类比。
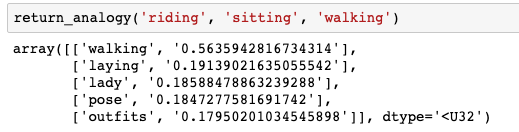
如果 riding 对应 sitting,那么 walking 对应什么呢?我的网络认为应该是 “laying”(这个结果还不错!)
同样,如果 “man” 的复数是 “men”,那么 “woman” 的复数应该是什么呢:
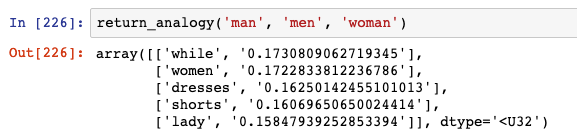
第二个结果是 “women”,相当不错了。
最后,如果 grass 对应 green,那么 sky 对应什么呢:

网络认为 sky 对应 silver 或 grey 的,虽然没有出现 blue,但它给的结果都是颜色词。令人惊讶的是,这个网络能够推断颜色的方向。
如果单词表示将类似的单词聚在一起,那么图像表示 (Inception 支持的图像编码器输出) 呢?我将相同的 t-SNE 技术应用于图像表示 (在 caption decoder 的第一步中作为输入的 300-dimensional tensor)。
可视化
这些点是不同图像的表示 (不是全部 8K 图像,大约是 100 张图像的样本)。红色箭头指向附近的一组表示的聚类。

赛车的图像被聚类在一起。
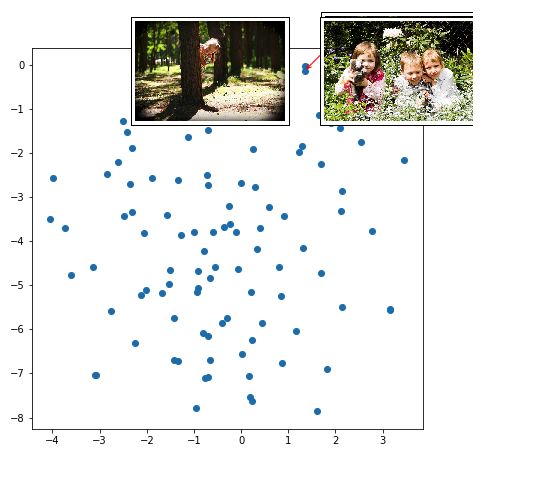
孩子们在森林 / 草地玩耍的图像也被聚类在一起。
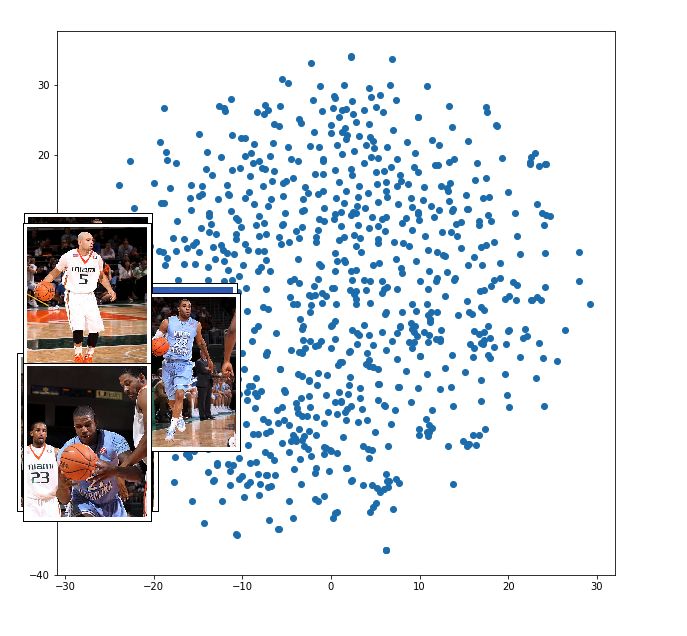
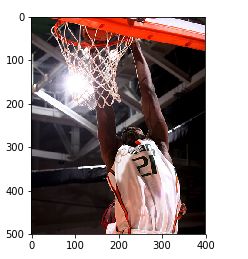
篮球运动员的图像被聚类在一起。
查找与输入图像相似的图像
对于查找相似单词任务,我们被限制在测试集词汇表中寻找相似的单词 (如果测试集中不存在某个单词,我们的 caption decoder 就不会学习它的嵌入)。然而,对于类似的图像任务,我们有一个图像表示生成器 (image representation generator),它可以接受任何输入图像并生成其编码。
这意味着我们可以使用余弦相似度方法来构建一个按图像搜索的功能,如下所示:
步骤 1:获取数据库或目标文件夹中的所有图像,并存储它们的表示 (由 image encoder给出)
步骤 2:当用户希望搜索与已有图像最相似的图像时,使用新图像的表示并在数据库中找到最接近的图像 (由余弦相似度给出)
谷歌图像可能正式使用这种 (或类似的) 方法来支持其反向图像搜索功能。
让我们看看这个网络是如何工作的:
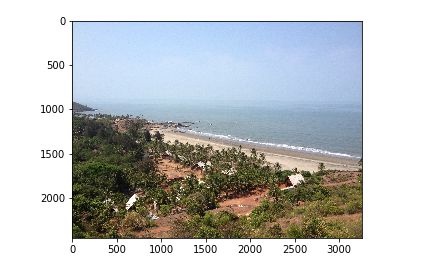
上面这张图像是我自己的。我们使用的模型以前从未见过它。当我查询类似图像时,网络从 Flickr8K 数据集输出如下图像:

是不是很像?我没想到会有这么好的表现,但我们确实做到了!
在最后一部分中,我们将反向运行 caption generator。因此,我们不是获取图像并为其生成标题,而是输入标题 (文本描述) 并找到与之最匹配的图像。
过程如下:
步骤 1:不是从来自编码器的 300 维图像表示开始,而是从一个完全随机的 300 维输入张量开始 步骤 2:冻结整个网络的所有层 (即指示 yTorch 不要计算梯度) 步骤 3:假设随机生成的输入张量来自 image encoder,将其输入到 caption decoder中 步骤 4:获取给定随机输入时网络生成的标题,并将其与用户提供的标题进行比较 步骤 5:计算比较生成的标题和用户提供的标题的损失 步骤 6:找到使损失最小的输入张量的梯度 步骤 7:根据梯度改变输入张量的方向 (根据学习率改变一小步) 继续步骤 4 到步骤 7,直到收敛或当损失低于某个阈值时为止 最后一步:取最终的输入张量,并利用它的值,通过余弦相似度找到离它最近的图像
结果相当神奇的:
我搜索了 “a dog”,这是网络找到的图像:

搜索 “a boy smiling”:

最后,搜索:

前两个结果是:

以及
所有这些操作的代码可以从 github 存储库下载执行: https://github.com/paraschopra/one-network-many-uses
这个存储库包括了用于数据预处理、模型描述、预训练的图说生成网络、可视化的代码。但不包括 Flickr8K 数据集或标题,需要单独下载。
如果你想更进一步,这里有一个挑战:从给定的描述生成图像。
这比本文中处理的要难 10 倍,但我感觉这是可行的。如果一项服务不仅能够搜索与文本对应的图像,而且能够动态地生成图像,那该多酷啊。
在未来,如果 Google Images 实现了这个功能,并能够为不存在的图像提供结果 (比如“两只独角兽在披萨做成的地毯上飞翔”),我不会感到惊讶的。
就这样。祝你能安全愉快地探索表示的世界。
参考链接: https://towardsdatascience.com/one-neural-network-many-uses-image-captioning-image-search-similar-image-and-words-in-one-model-1e22080ce73d
| 


 发表于 2019-3-14 19:24:28
发表于 2019-3-14 19:24:28